pytesseract windows 安裝教學

pytesseract 安裝教學
pip install pytesseract
pytesseract 函數庫
https://github.com/UB-Mannheim/tesseract/wiki
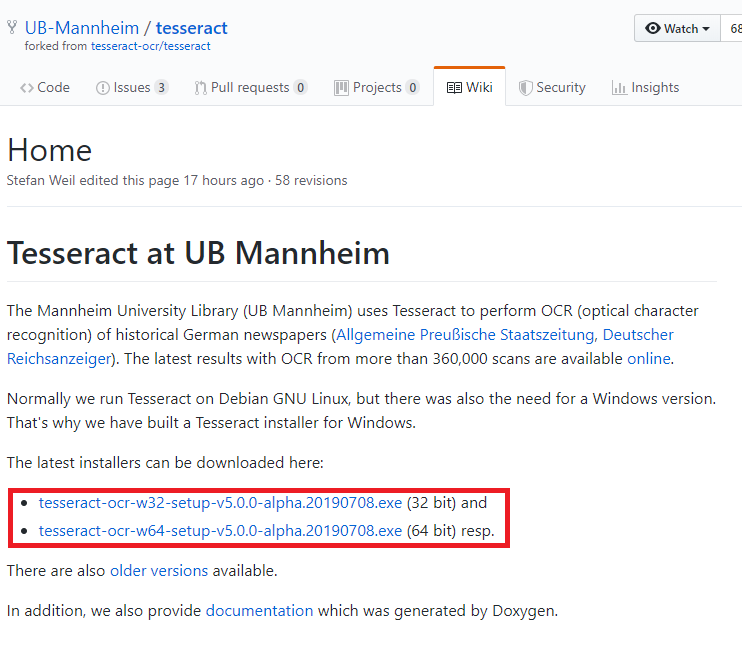
依據電腦系統規格下載適合的函數庫
# 辨識教學範本 import pytesseract import pyautogui import cv2 pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe' config = '--psm 8 --oem 3 -c tessedit_char_whitelist=0123456789' pyautogui.screenshot(r'C:\Users\jojo\Desktop\1235.png',region=(82, 271, 39 ,16)) img = cv2.imread(r"C:\Users\jojo\Desktop\1235.png") orc = pytesseract.image_to_string(img, config=config) print(orc) # 印出辨識的文字
# config 參數
# 0 Orientation and script detection (OSD) only.
# 1 Automatic page segmentation with OSD.
# 2 Automatic page segmentation, but no OSD, or OCR.
# 3 Fully automatic page segmentation, but no OSD. (Default)
# 4 Assume a single column of text of variable sizes.
# 5 Assume a single uniform block of vertically aligned text.
# 6 Assume a single uniform block of text.
# 7 Treat the image as a single text line.
# 8 Treat the image as a single word.
# 9 Treat the image as a single word in a circle.
# 10 Treat the image as a single character.
# 11 Sparse text. Find as much text as possible in no particular order.
# 12 Sparse text with OSD.
# 13 Raw line. Treat the image as a single text line, bypassing hacks that are Tesseract-specific.







Leave a Comment